
A mai IT-környezetek gyorsak, összetettek és állandó mozgásban vannak. A különálló monitoring eszközök önmagukban már nem képesek biztosítani azt az átláthatóságot, amire az üzemeltetésnek, fejlesztésnek és biztonsági csapatoknak szüksége van. Ebben a cikkben a Dynatrace példáján keresztül bemutatjuk, mit jelent a teljes körű (end-to-end) observability, és milyen szempontokat érdemes figyelembe venni a megvalósítás során.
Mindent monitorozunk, miért nem látjuk át mégsem, hogy mi történik?
Az IT-rendszerek történetében még sosem gyűjtöttünk ennyi adatot, és ennek ellenére soha nem volt még ilyen kevés valós válaszunk. Monitoring eszközökből nincs hiány – a legtöbb szervezetnél több is működik párhuzamosan. Az egyik az infrastruktúrát figyeli, a másik a kódot, a harmadik a hálózatot, a negyedik a felhasználói élményt.
Mégis, amikor egy rendszer lelassul, egy sérülékenység kikerül a nyilvánosság elé, vagy egy frissítés váratlan hibát okoz – a kérdés ugyanaz:
Ki tudja pontosan megmondani, mi történik most? És miért?
A különálló eszközök különálló válaszokat adnak. Ez vezet el oda, hogy nagy mennyiségű információ áll rendelkezésre, de nem látjuk köztük az összefüggéseket.
A megoldás: Több külön monitoring eszköz helyett egyetlen egységes observability platform bevezetése, amely teljes átláthatóságot biztosít.
Mit jelent ma az, hogy „teljes körű megfigyelhetőség”?
A teljes körű megfigyelhetőség (end-to-end observability) azt jelenti, hogy az IT-környezet minden szintjéről – az infrastruktúrától kezdve az alkalmazáslogikán és a felhasználói élményen át az üzleti folyamatokig – automatikusan és valós időben gyűjtünk adatokat, amelyeket egy egységes platformon kontextusban értelmezünk.
Egységes observability platform, pl. Dynatrace nélkül az IT-csapatok különböző nézőpontokból próbálják értelmezni az eseményeket – mindenki a saját eszközét, a saját szemszögét használja. Nincs közös kiindulópont, ezért nehéz valódi felelősséget vállalni a megoldásért.
Az end-to-end observability ezt a problémát oldja fel azzal, hogy egy platformon belül egységes képet ad: a kiváltó ok, az érintett szolgáltatások, a biztonsági kockázat és az üzleti hatás is azonnal láthatóvá válik ugyanannak az eseménynek a részeként.
Ez három szinten történik meg:
- Technikai lefedettség – Az infrastruktúrától a kód szintig, a felhasználói interakcióktól a hálózati forgalomig minden elem valós időben látható.
- Biztonsági integráció – A sérülékenységek, hibák és konfigurációs problémák nemcsak listázva, hanem priorizálva, kontextusban jelennek meg.
- Üzleti összekapcsolás – Nemcsak technikai metrikákat látunk, hanem azt is, hogy egy hiba milyen szolgáltatást, ügyfelet vagy bevételt érint.
Full-stack és end-to-end observability – mi a különbség?
Számos szervezet már elérte a full-stack observability szintjét: képesek adatot gyűjteni az infrastruktúra, az alkalmazások, az adatbázisok és a felhasználói interakciók szintjén. Ez technikai értelemben teljes lefedettséget jelent – de önmagában még nem garantálja, hogy az IT-csapatok átlátják a rendszer egészének működését, és értik, hogy egy adott esemény miért következett be, illetve milyen hatása van.
Az end-to-end observability ezt a korlátot lépi át. Nemcsak minden technikai réteget figyel, hanem összeköti ezeket az adatokat üzleti, biztonsági és felhasználói kontextussal is. A cél az értelmezés: annak pontos megértése, hogy egy esemény mit jelent a szervezet egésze szempontjából – és milyen beavatkozás szükséges.
Az end-to-end megközelítés tehát a technikai lefedettség mellett, egy egységes, kontextus-alapú döntési keretet is jelent, amely azáltal, hogy megmutatja az üzleti folyamat teljes egészét, lehetővé teszi a gyors és megalapozott beavatkozást.
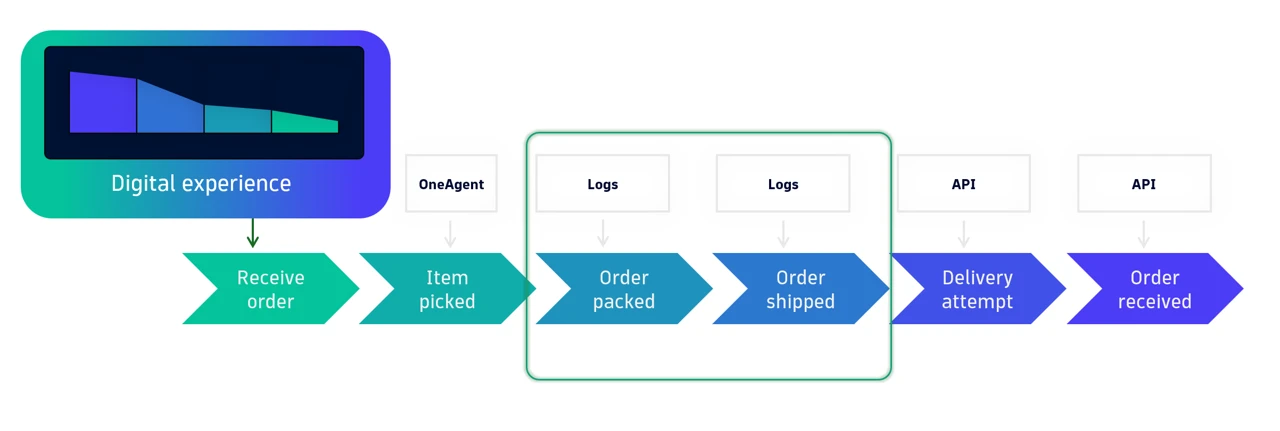
Mit nyújt egy teljes körű observability platform?
Egy korszerű observability platform nemcsak adatokat gyűjt, hanem az alábbi képességeket is biztosítja:
- Full-stack observability – A rendszer minden rétegét lefedi az infrastruktúrától a felhasználói élményig. Így az események nem elszigetelten, hanem összefüggéseikben láthatóak.
- Valós idejű sebezhetőség-elemzés – A sérülékenységeket detektálja és priorizálja az üzleti hatások figyelembevételével.
- Security posture management – Felhő és Kubernetes környezetekben segít az automatikus konfiguráció-javításban és megfelelőség biztosításában.
- Observability a fejlesztőknek – Segít megérteni, hogyan viselkedik a kód éles környezetben, így a biztonság már a fejlesztési ciklusban érvényesül.
- Platform engineering és SRE támogatás – Egyszerűsíti az üzemeltetési eszközkészletet, és elősegíti a megbízhatósági célok elérését.
- Környezeti hatás mérése – Láthatóvá teszi a rendszerterhelés karbonlábnyomát, ami fontos szempont lehet a fenntarthatósági célok elérésében.
- Automatizált megfelelés – Segít a gyorsan változó szabályozási környezet követésében és a jelentési kötelezettségek teljesítésében.
*A fent említett képességek elérhetősége régiótól függően változhat.
Melyek a legfontosabb szempontok az end-to-end observability megvalósításánál?
A legtöbb szervezet nem nulláról indul: már rendelkeznek különböző monitoring eszközökkel, részleges rálátással és adatgyűjtéssel. A kérdés nem az, hogy van-e adat, hanem az, hogy ezekből az adatokból lehet-e következetes, megbízható és kontextusban értelmezhető képet alkotni – minden rétegről, minden eseményről, valós időben. Az end-to-end observability megvalósítása éppen ezt a célt szolgálja.
A siker kulcsa három fő szempont:
1. Képes-e a rendszer előre jelezni a teljesítményproblémákat?
A legnagyobb összesített üzleti veszteséget nem a ritka, súlyos események – például egy teljes rendszerleállás –, hanem a gyakori, kisebb hatású problémák okozzák, mint például a rejtett lassulások vagy instabil felhasználói élmény. Olyan platformot érdemes választani, amely nemcsak érzékeli a hibákat, hanem képes megelőzni azokat: például azáltal, hogy ok-okozati gráfokat elemez, eseményláncokat tár fel, és proaktívan javasol beavatkozást – akár automatikus visszagörgetéssel vagy erőforrás-átcsoportosítással. Ilyen típusú képességeket kínálnak a fejlettebb rendszerek, például a Dynatrace Davis AI motorja, amely nemcsak észlel, hanem okot is azonosít.
2. Valóban átlátható a felhős és konténeres környezet?
Multicloud működés és Kubernetes esetén gyakori, hogy a hagyományos monitoring eszközök nem látják az egyes szolgáltatások közötti dinamikus kapcsolatokat, rövid életű entitásokat vagy éppen a cloud providerhez kötött részleteket. Érdemes olyan megoldást keresni, amely natívan képes adatot gyűjteni a legfontosabb felhőszolgáltatóktól (AWS, Azure, GCP), és mélységében ismeri a Kubernetes működését – beleértve a pod-topológiát, erőforrás-használatot és konfigurációs állapotokat. A Dynatrace ebben is támogatást nyújt, valós idejű láthatóságot biztosítva a konténeres architektúrák legmélyebb szintjein is.
3. Milyen szinten értelmez a rendszer? Csak jelez, vagy meg is magyaráz?
Sok megoldás statisztikai korrelációk alapján működik, de ez gyakran nem elég egy összetett környezetben. Ha az IT-csapatok csak valószínűségi alapon dolgoznak, könnyen előfordulhat, hogy rossz helyen keresik a hibát. Olyan platformot érdemes választani, amely ok-okozati elemzést végez, és pontosan meg tudja mutatni, hogy mely esemény váltott ki egy másikat. A causal AI-alapú megközelítések – mint amilyet a Dynatrace is alkalmaz – nemcsak gyorsabb reagálást tesznek lehetővé, hanem a beavatkozás pontosságát is javítják.
A Telvice olyan szervezetek partnere, amelyek célja az átláthatóbb és hatékonyabb IT-működés megteremtése. Támogatást nyújtunk a tervezéstől egészen a megvalósításig. Ingyenes konzultációért vedd fel velünk a kapcsolatot!
