
A generatív mesterséges intelligencia (AI) látványos térhódítása ellenére a technológia működése a nem körültekintő használat esetén kiszámíthatatlan és nehezen kontrollálható lehet. A nagy nyelvi modellek (LLM-ek) hallucinálhatnak, vagyis valóságtól elrugaszkodott válaszokat adhatnak. Előfordulhat szenzitív adatok kiszivárgása, és vállalati környezetben megugorhatnak az üzemeltetési költségek is.
A megoldás nem a generatív MI korlátozása, hanem annak átláthatóvá tétele. A modern observability eszközök már nemcsak mikroszolgáltatásokat és infrastruktúrát képesek figyelni, hanem a mesterséges intelligencia komponenseinek működését is. Ez pedig új korszakot nyithat az AI-rendszerek bevezetésében: az obszerválható AI nem feketedoboz többé, hanem mérhető, visszakereshető és optimalizálható.
Mi az LLM Observability – és miért van rá szükség?
A generatív MI rendszerek egyik legnagyobb kihívása, hogy nem látszik, mi történik a háttérben. Egy felhasználó beír egy kérdést, a rendszer pedig válaszol – de mi zajlik a színfalak mögött? Milyen adatokból dolgozik a modell? Mennyi ideig tart a válasz generálás? Miért került ennyibe egy lekérdezés? És vajon tartalmazott-e érzékeny adatot az, amit a modell kiküldött?
A válaszokhoz az Observability segíthet hozzá. Mi lenne, ha nemcsak az infrastruktúrát és alkalmazáslogikát lehetne figyeli, hanem a promptokat, tokenhasználatot, modellválaszokat és költség paramétereket is?
Pontosan ezt célozza meg a Dynatrace és az Amazon közös megoldása. Az Amazon Bedrock biztosítja a generatív AI modellek (pl. Anthropic Claude, Mistral, Meta Llama) hozzáférését, míg a Dynatrace – a Davis AI motorral és OpenTelemetry-alapú megfigyeléssel – képes valós időben nyomon követni a teljes pipeline működését.
A két technológia integrációja révén:
- láthatóvá válnak az LLM-ek válaszideje, stabilitása és verzióváltásai (model fingerprinting),
- mérhető és előrejelezhető a token használat és az MI-működés költsége. Ha van hozzáférésed a Dynatrace Playgroundhoz, itt tudod megnézni a dashboard-okat: https://dynatr.ac/4dnkuLX
- automatikusan észlelhetők a prompt injection támadások, érzékeny adatmozgások és nem megfelelő válaszok.
Hogyan működik az LLM Observability a gyakorlatban?
Ahhoz, hogy egy generatív MI alkalmazás megfigyelhetővé váljon, az egész pipeline-t át kell látni – az első felhasználói interakciótól az LLM válaszáig és azon is túl. Ez több technológiai réteg együttműködését igényli, amelyeket a Dynatrace egységes platformként képes követni, mérni és vizualizálni.
A megoldás a következő fő komponenseken alapul:
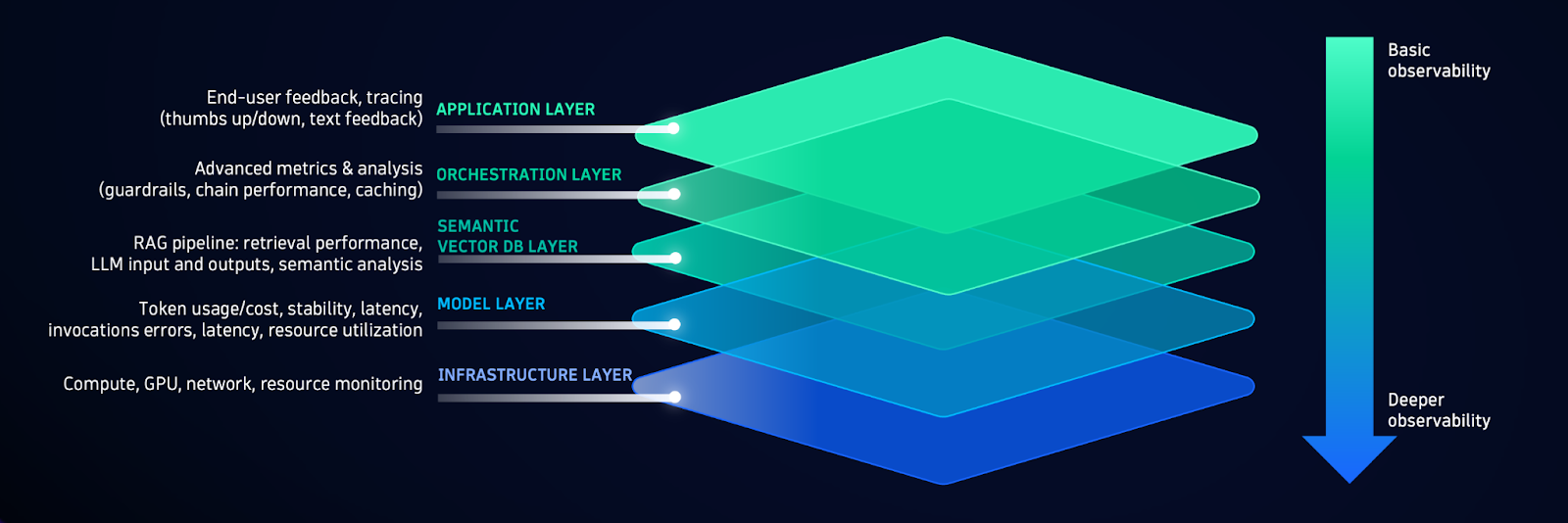
1. Application Layer – Felhasználói élmény megfigyelése
Ez a réteg kapcsolja össze az LLM-et a végfelhasználóval. A Dynatrace itt figyeli:
- a válaszidőt,
- a felhasználói interakciókat (pl. keresések, lekérdezések),
- a hibák előfordulását és
- a rendszerhasználat mintázatait.
Mindez segít abban, hogy az MI-alapú élmény megbízható és gyors maradjon.
2. Orchestration Layer – A prompt pipeline nyomon követése
A generatív MI alkalmazások gyakran használnak prompt-összefűző vagy „orchestration” keretrendszereket, mint például a LangChain. Ezek felelősek azért, hogy:
- milyen adatokat illesztünk be a promptba,
- hogyan kapcsolódnak egymáshoz a komponensek (pl. keresés, kérdésfelvetés, válaszgenerálás).
A Dynatrace ezen a szinten képes az egyes láncszemek teljesítményét mérni, hibákat azonosítani, és trace-szinten követni, hogy hol lassult le vagy torzult el a feldolgozás.
3. Semantic Layer – Adatgazdagítás figyelése
Gyakori technika, hogy a nyelvi modellt nemcsak a kérdéssel, hanem extra információkkal (RAG – Retrieval Augmented Generation) is ellátják. Ezt például Pinecone vagy más vektor-adatbázis végzi.
Itt fontos figyelni:
- az adatok relevanciáját (segít vagy zavar az információ),
- az elérési időt (lassíthatja az MI válaszát),
- és a hibákat (rossz keresés → rossz válasz).
A Dynatrace ezen a szinten is méri a keresési műveletek minőségét és idejét, és képes alertelni, ha például egy vektor-adatbázis túl lassú vagy hibás adatot ad vissza.
4. Model Layer – A modell viselkedésének követése
Ez az LLM szíve. A Dynatrace figyeli itt:
- a tokenhasználatot (input/output),
- a válaszidőt és stabilitást,
- az anomáliákat a kimenetekben (hallucináció, torzítás),
- a modell verzióját (model fingerprinting) audit céljából.
Ezáltal lehetővé válik például az, hogy ha egy modellváltozás miatt megugrik a válaszidő vagy romlik a válasz minőség, az azonnal látható legyen.
5. Infrastructure Layer – GPU, CPU, hálózat megfigyelése
Végül, de nem utolsósorban, a generatív MI hatalmas számítási kapacitást igényel – különösen, ha saját Kubernetes környezetben fut. A Dynatrace figyeli:
- GPU/CPU kihasználtságot,
- memória- és sávszélesség használatot,
- infrastruktúra hibákat, amelyek hatással lehetnek a válaszidőre vagy elérhetőségre.
Mindez egyetlen trace-ben összeáll
A Dynatrace minden egyes felhasználói kérésre egy teljes trace-et épít, amely:
- mutatja, mi történt,
- hol volt a torlódás,
- mennyi erőforrást használt az adott válasz,
- és milyen adatútvonalon keresztül született meg.
Ezáltal a fejlesztői, üzemeltetői, biztonsági és üzleti csapatok ugyanazt az adatot látják – valós időben.
Nézd meg, hogyan működik a gyakorlatban: AI and LLM Observability with Dynatrace – YouTube
Az LLM Observability már elérhető Magyarországon
Az Amazon Bedrock (pl. Anthropic Claude, Mistral, Meta Llama) elérhető az EU-ban, beleértve a frankfurti régiót is, és ez azt jelenti, hogy akár Magyarországról is használható, mivel az AWS régiók globálisan hozzáférhetőek. Ha van hozzáférésed a Bedrock API-hoz, akkor egy Dynatrace fiókkal aktiválhatod az LLM Observability funkciókat – nincs szükség külön magyarországi telepítésre.
A Traceloop OpenLLMetry (pl. Traceloop SDK) segítségével Bedrock-promptokat és válaszokat tudsz monitorozni, amelyek közvetlenül bekerülnek a Dynatrace rendszerébe – néhány perc beállítás, és máris rálátsz a teljes AI-pipeline-ra. A Dynatrace AI/LLM Observability aktiválása egyszerű: csak egy API-token és endpoint beállítása szükséges, és azonnal működik a teljes MI-folyamat figyelése.
Próbáld ki saját magad, és telepítsd a generatív AI demó alkalmazást a GitHub Codespace segítségével: https://github.com/Dynatrace/obslab-llm-observability/tree/ollama-pinecone
Valósítsd meg az AI observability-t a saját környezetedben a részletes Dynatrace dokumentáció segítségével: https://docs.dynatrace.com/docs/analyze-explore-automate/dynatrace-for-ai-observability/get-started/sample-use-cases/self-service-ai-observability-tutorialA Telvice-nél világelső technológiák alkalmazásával támogatjuk vállalata átlátható és hatékony működést. Kérjen szakértői konzultációt, és kezdje meg a digitális átalakulás következő szakaszát velünk!
